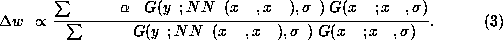For a complete pattern 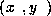 ,
the weight update of a backpropagation step for
weight
,
the weight update of a backpropagation step for
weight  is
is
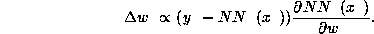
Using the approximation of Equation 1, we obtain for an incomplete data point (compare Tresp, Ahmad and Neuneier, 1994)
Here, 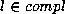 indicates the sum over complete patterns
in the training set,
and
indicates the sum over complete patterns
in the training set,
and  is the standard deviation of the output noise.
Note that the gradient is a network of normalized Gaussian basis
functions where the ``output-weight'' is now
is the standard deviation of the output noise.
Note that the gradient is a network of normalized Gaussian basis
functions where the ``output-weight'' is now
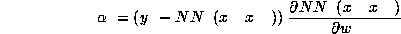
The derivation of the last equation can be found in the Appendix. Figure 3 shows experimental results.
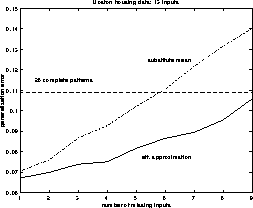
Figure: In the experiment, we used the Boston housing data set, which
consists of 506 samples. The task is to predict the housing price
from 13 variables which were thought to influence the housing price in a neighborhood.
The network (multi-layer perceptron)
was trained with 28 complete patterns plus an additional
225 incomplete samples. The horizontal axis indicates how many inputs
were missing in these 225 samples. The vertical axis shows the generalization
performance. The continuous line indicates the performance of our approach
and the dash-dotted line indicates the performance,
if the mean is substituted for a missing variable. The dashed line indicates
the performance of a network only trained with the 28 complete patterns.